Научный отчет за 1997 г. по гранту РФФИ No. 97-07-90148
Название проекта: Разработка высоко-параллельной масштабируемой системы управления базами данных для мультипроцессорной вычислительной системы без совместного использования ресурсов
Руководитель: Соколинский Леонид Борисович
Содержание
Аппаратная архитектура системы Омега
Программная архитектура системы Омега
Стратегия размещения данных в системе Омега
Архитектура прототипа системы Омега
Оптимизация запросов в системе Омега
Целью данного проекта является создание параллельной СУБД для отечественной многопроцессорной вычислительной системы МВС-100/1000 разработки НИИ "Квант" Роскомоборонпрома, ИПМ им. М.В. Келдыша РАН, ИММ УрО РАН и ВНИИЭФ Минатома. Данная СУБД должна обеспечивать эффективную обработку запросов на основе глубокого распараллеливания. СУБД должна поддерживать обработку и хранение в базе данных объектов сложной структуры.
Интенсивные научные исследования по данной тематике начали проводиться в 80-х годах в нескольких западных университетах и научных лабораториях. К настоящему времени создано несколько систем и прототипов параллельных СУБД для платформ с массовым параллелизмом. К ним относятся DB2 Parallel Edition [1], Bubba [2], Gamma [3]. Однако до настоящего времени в области параллельных баз данных остается много нерешенных проблем фундаментального характера [4].
Модульный принцип построения МВС дает большие возможности для создания различных аппаратных конфигураций, в первую очередь за счет изменения топологии соединения процессорных модулей высокоскоростными каналами связи - линками. При этом архитектура МВС базируется на следующих константных принципах, являющихся фундаментом потенциальной мобильности программного обеспечения для различных линий МВС:
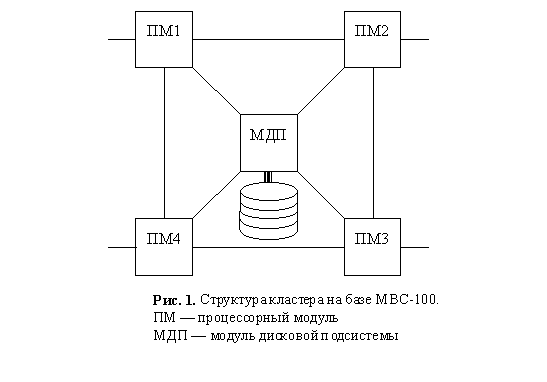
На базе этих требований была разработана оригинальная аппаратная архитектура системы Омега. Основная идея заключается в двухуровневой организации системы. Единицей масштабирования системы является так называемый кластер. Кластер имеет сильно связанную структуру и состоит из четырех процессорных модулей и дисковой подсистемы с четырьмя дисковыми накопителями на общей SCSI шине. Каждый процессорный модуль соединен посредством линков с двумя другими процессорными модулями и дисковой подсистемой. Один линк каждого процессорного модуля остается свободным и используется для соединения кластеров между собой. Таким образом, каждый кластер имеет четыре внешних линка.
В минимальной конфигурации система может состоять из двух кластеров. В общем случае система может включать в себя несколько сотен кластеров. Топология межкластерных соединений не фиксируется. Предполагается что она имеет относительно низкую степень связности. В простейшем случае кластеры образуют двусвязную "линейку", на концах которой стоят две host-машины. Подобная архитектура уже образует систему, отказоустойчивую по всем аппаратным компонентам.
Предложенная архитектура занимает промежуточное место между архитектурой без совместного использования ресурсов и архитектурой с разделением дисков. Пропускная способность SCSI шины примерно на порядок превышает пропускную способность линка, поэтому общее быстродействие системы будет такое же, как у системы с отдельной дисковой подсистемой на каждый вычислительный модуль. Предполагается, что внутри кластера за каждым процессорным модулем закреплен один диск. Процессорный модуль вместе с закрепленным за ним диском образует узел. При этом считается что процессорные модули одного кластера не могут использовать диски других кластеров.
Описанная архитектура допускает высокую степень масштабируемости и потенциально способна обеспечить ускорение и расширяемость, близкие к линейным. Данная архитектура позволяет достигнуть приемлемого баланса загрузки процессоров, что является основной проблемой для систем без совместного использования ресурсов, и избежать сложностей, связанных с проблемой согласования данных в кэш памяти различных процессоров, что характерно для систем с совместным использованием дисков.
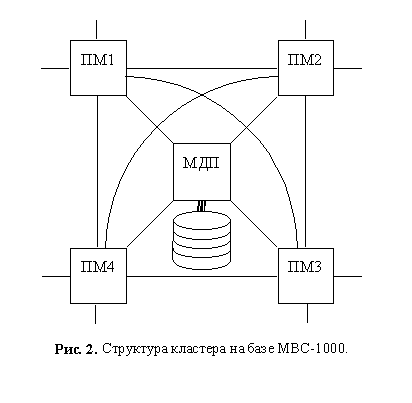
Описанная выше структура кластера, основывалась на аппаратных особенностях МВС-100. Однако она легко адаптируется и для МВС-1000.
В этом случае структура кластера количественно не меняется, но увеличивается степень его внутренней связности (каждый процессорный модуль соединяется с каждым), и для межкластерных связей отводится уже восемь линков. В случае МВС-1000 простейшей топологией системы является двумерная матрица кластеров.
На основе предложенной аппаратной архитектуры были разработаны принципы построения программной архитектуры системы Омега. На начальном этапе были сформулированы следующие требования к программной архитектуре системы.
В соответствие с указанными требованиями была спроектирована программная архитектура системы Омега [7]. В основу архитектуры заложен трехуровневый принцип организации системы.
Первый уровень составляет маршрутизатор, обеспечивающий передачу сообщений и данных между кластерами. Маршрутизатор обладает полным знанием топологии межкластерных соединений, информацией о работоспособности линий связи (линков) и их текущей загрузке. На основе этой информации маршрутизатор пытается выбрать оптимальный путь передачи сообщения от одного кластера к другому, однако, в общем случае, маршрут, выбранный маршрутизатором, может и не быть "самым" оптимальным. Маршрутизатор позволяет полностью абстрагировать реализацию СУБД Омега от топологии межкластерных соединений. Если рассматривать маршрутизатор как виртуальное устройство, то архитектура системы в целом принимает звездообразную структуру: в центре звезды расположен маршрутизатор, линки образуют лучи, на концах которых расположены кластеры. Реализация маршрутизатора строится на базе ОС Router разработки ИПМ им. М.В. Келдыша РАН. В перспективе может быть выполнена аппаратно-программная реализация маршрутизатора с использованием специальной элементной базы.
Второй уровень описывает системную структуру кластера и включает в себя кондуктор, подсистему ввода-вывода, утилиты и ядро СУБД. Кондуктор играет роль маршрутизатора внутри кластера. В связи с простой фиксированной топологией кластера кондуктор всегда обеспечивает оптимальный выбор маршрута для передачи сообщений и данных внутри кластера. За основу реализации кондуктора берется ОС Router, оптимизированная для структуры кластера и специфики СУБД. Подсистема ввода-вывода реализует низкоуровневые файловые операции и абстрагирует СУБД от аппаратных особенностей модуля дисковой подсистемы. В основе подсистемы ввода-вывода лежит механизм станичной организации внешней памяти с поддержкой блокировки страниц и кэширования данных. Ядро СУБД обеспечивает параллельное выполнение реляционных операций, составляющих часть плана выполнения запроса, возложенную на данный кластер. Утилиты представляют собой набор сервисных функций, обеспечивающих согласование данных, реплицированных на различных дисках внутри и во вне кластера, ведение журнала изменений и др.
Третий уровень включает в себя обработчик запросов, планировщик и менеджер данных. Обработчик запросов выполняет трансляцию запроса с языка манипулирования данными во внутреннее представление с последующей оптимизацией и получением параллельного плана выполнения запроса. Планировщик, используя информацию о текущей загрузке системы и распределении данных, распределяет параллельный план по конкретным кластерам. Менеджер данных формирует и обновляет информацию о структуре базы данных, декластеризации, репликации и размерах отношений и др. Менеджер данных используется обработчиком запросов для получения оптимального параллельного плана, и планировщиком для корректного и эффективного разбиения плана по кластерам. Третий уровень может быть частично или полностью реализован на host-машине.
Декластеризация. Каждое декластеризуемое отношение разбивается на количество частей, кратное некоторому числу, равному, например, количеству узлов кластера, в данном случае четырем. Указанные четверки распределяются по кластерам. Внутри каждого кластера, участвующего в распределении отношения, все четыре части отношения реплицируются на каждом диске кластера (скрытая репликация). При поступлении в кластер некоторых операторов от планировщика они начинают параллельно выполняться, каждый на отдельном узле. Если перекоса данных не имеется, то каждый узел последовательно обрабатывает все четыре части соответствующего отношения. В случае наличия перекосов данных один из узлов "досрочно" заканчивает выполнение своего оператора. В этом случае он опрашивает остальные узлы кластера. При нахождении наиболее загруженного узла, он переключается на выполнение соответствующего оператора. При этом он использует реплики тех частей соответствующего отношения, которые еще не были обработаны.
Распределение записей. При распределении записей отношения по кластерам используется принцип "теплоты" [2]. Первоначально записи распределяются по кольцевому принципу: каждая следующая запись записывается на следующий кластер, содержащий данное отношение. После первоначального распределения включается распределение по принципу "теплоты".
Репликация. В целях обеспечения отказоустойчивости системы при отказе дисковой подсистемы кластера вводится обязательная межкластерная репликация. Каждая запись каждого отношения хранится как минимум в двух различных кластерах. Распределения записей в различных межкластерных репликах одного и того же отношения осуществляются независимо и могут отличаться друг от друга. Это необходимо для варьирования выбора реплики. При поступлении оператора, планировщик анализируя оператор дает его на выполнение наиболее подходящей реплике. Реплика выбирается исходя из свойств оператора и информации из базы данных, собранной до этого в так называемом репозитории перекосов. На основе этой информации выбирается реплика с наименьшим перекосом по кластерам для данного оператора. В качестве стратегии согласования межкластерных реплик предполагается использовать темпоральный подход.
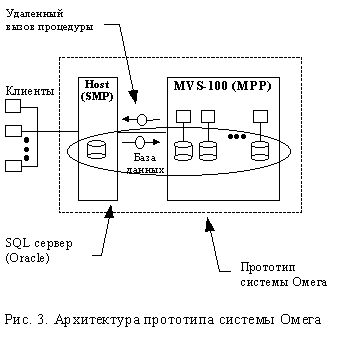
Разработана архитектура прототипа системы Омега, допускающая промышленное использование системы на ранних этапах разработки [7]. В соответствие с этой архитектурой на начальном этапе параллельная машина баз данных для МВС реализуется в виде некоторого набора библиотечных функций. МВС подключается к Host-машине, на которой устанавливается ОС Linux. Host-машина, в свою очередь, подключается к Oracle-серверу. В простейшем случае Oracle-сервер может располагаться на host-машине. Приложение разрабатывается средствами СУБД Oracle. При этом в программный код включаются вызовы соответствующих функций библиотеки Омега, хранящейся на host-машине. Программный интерфейс реализуется по образцу удаленного вызова хранимых процедур.
В качестве возможного варианта вместо Oracle может использоваться свободно распространяемая СУБД Postgres95.
В качестве языка данных системы Омега предложен новый язык манипулирования данными [6]. Язык основан на реляционной модели и при этом оснащен средствами поддержки новых возможностей, присущих объектной ориентации, которые являются ортогональными по отношению к реляционной модели. В основу архитектуры языка заложена концепция персистентных объектов. Таким объектом может быть, например, скалярное значение, реляционная таблица, кластер (набор реляционных таблиц) или база данных в целом. С каждым объектом связываются операции (методы). Классическая ACID-транзакция рассматривается как частный случай операции над кластером. Все операции над персистентными объектами, независимо от природы объекта, должны допускать возможность отката. В этом смысле каждая операция является транзакцией. Вход в транзакцию осуществляется неявно в начале выполнения операции. Фиксация также происходит неявно при нормальном завершении операции. Откат происходит в результате возникновения явной или неявной исключительной ситуации. Ограничения целостности предполагается сделать универсальными атрибутами объектов. При этом объекты хранятся в базе данных вместе со своими операциями и ограничениями целостности. В качестве механизма поддержки транзакций предполагается использовать темпоральный подход.
В предложенном языке в рамках реляционной модели осуществлена поддержка объектов сложной структуры. Основной идеей является введение для каждого типа данных реализационного фрейма. Реализационный фрейм является аналогом абстрактного типа данных (АТД). Однако, в отличие от АТД, структура реализационного фрейма предопределяется спецификой реляционной модели. Реализационный фрейм создается и заполняется для каждого нового нестандартного типа данных, и содержит, по существу, реализацию базовых операций над объектами данного типа, позволяя сохранить полную функциональность реляционной модели применительно к нестандартному типу. При определении реализационного фрейма предполагается использовать принципы многоуровневой инкапсуляции и "вертикального" слоения, предложенные в работах [9, 10]. С каждым уровнем и слоем связывается предопределенная семантика. Данный подход позволяет автоматизировать заполнение реализационного фрейма на 60-80% [11].
Центральным звеном оптимизации запросов является стоимостная модель. Несмотря на то, что стоимостные модели для реляционных запросов, выполняемых на одном процессоре, детально разработаны, проблема разработки эффективных и точных стоимостных моделей обработки запросов на многопроцессорных конфигурациях в большей степени до сих пор остается открытой [5].
Существует два подхода к построению стоимостных моделей. При первом подходе процесс оптимизации запроса делится на два этапа. На первом этапе находится план, оптимальный для последовательного исполнения. На втором этапе происходит поиск оптимального разбиения этого плана по процессорам для параллельного выполнения. Фактически это приводит к возникновению двух независимых стоимостных моделей. При втором подходе строится единая стоимостная модель, включающая в себя задачу разбиения плана выполнения запроса по процессорам. Второй подход позволяет строить более точные стоимостные модели, однако он является и более сложным.
Для СУБД Омега в начальном варианте разработана оригинальная стоимостная модель для параллельной оптимизации запросов [8]. При этом был использован второй подход. В основе предложенной стоимостной модели лежат коэффициенты распараллеливания, селективности и трудоемкости реляционных операций. На основе этих коэффициентов была построена стоимостная функция, позволяющая из множества планов выбрать оптимальный. Предложенная стоимостная модель включает в себя задачу распределения процессоров. В дальнейшем предполагается уточнить разработанную стоимостную модель, таким образом, чтобы учитывались коммуникационные затраты и информация о распределении данных по дискам.
В ходе первого года работ по проекту были получены следующие результаты:
Результаты, полученные в ходе данного проекта докладывались на одной всероссийской и двух международных конференциях, и находятся в русле современных научных исследований в области параллельных баз данных.